
What is GenStage and How to use GenStage to Consumer Twitter API Forever
18 minutes to readGuide Gist
GenStage are Elixir behaviors for exchanging events with back-pressure between Elixir processes
Here you will learn how to set up gen_stage, create a producer and a consumer, and use backpressure to control when to get more tweets from the Twitter API. We will learn how to create multiple consumers to consume from one producer and how the consumers, producers, and producer-consumers work. I hope this article finds you well, and I hope, in the end, you will have more knowledge about GenStage.
But if you really want to learn GenStage in depth and learn about other ways of using concurrency with elixir the book Concurrent Data Processing With Elixir - by Svilen Gospodinov is the go to book if you want to learn more about data processing with elixir.
Now, put your seatbelt because this will be a fun ride.
GenStage for people in a hurry
GenStage has two main components called Producer and Consumer, and as the name suggests, the producer gets the data or produces the data that is passed to the consumer to process it. We can have multiple consumers consuming data from a producer, which is usually the case because we often want to consume data in parallel. Compared to other solutions, GenStage is n orders of magnitude simpler.
I will give you a simple example first so you can understand how we can connect both pieces together. But you are here to a more detailed explanation go here .
Producer
As the name suggests, the producers are responsible for getting the data you need. You can get data from whatever you want. There is no limit here. You only need to implement the functions required by the GenState “interface”. Here is a simple example of a producer that will get a string and send letters to the consumers one by one.
defmodule Post.Producer do
use GenStage
def start_link(sentence \\ "") do
GenStage.start_link(__MODULE__, sentence, name: __MODULE__)
end
def init(initial_state) do
{:producer, initial_state}
end
def handle_demand(demand, state) do
IO.inspect("Demand: #{demand}, state: #{state}", label: "STATE")
letters =
state
|> String.graphemes()
letters_to_consume = Enum.take(letters, demand)
sentence_left = String.slice(state, demand, length(letters))
{:noreply, letters_to_consume, sentence_left}
end
endThis producer will break a sentence into letters and send to the consumer based on the consumer’s demand. The important function here is the
def handle_demand(demand, state)
This function will be called every time the consumer request more data. The consumer will send how much data it wants to consume. The producer can also store the latest state of the data it has been processing, and that is why we create the sentence_left variable so we can return that to the state.
In summary, what this function is doing is:
- break a sentence into letters
- Get the number of letters to send to consumers based on the demand
- removing the letters that were sent from the original sentence
-
returning a tuple with the atom
:noreply, the letters that will send to the consumer, and the latest state, with all the letters that was not sent to the consumer yet.
The consumer will then process the events sent (the letters) and call the producer again. The producer will repeat the process using the latest state, which is the up-to-date sentence already without the letters from the first round. And this process will continue until the producer has nothing else to send to the consumer.
It’s time to take a look at the consumer.
Consumer
The consumer’s job is to generate demand for the producer. Even though the producer has a ton of data, they will only send it if the consumer asks. And the consumer does this in multiple ways. Right now, you will learn how to configure the consumer demand statically, and you will learn the main consumer function handle_events
defmodule Post.Consumer do
use GenStage
require Logger
alias Post.Producer
def start_link(args \\ "") do
GenStage.start_link(__MODULE__, args)
end
def init(args) do
Logger.info("Init Consuming words")
subscribe_options = [{Producer, min_demand: 0, max_demand: 10}]
{:consumer, args, subscribe_to: subscribe_options}
end
def handle_events(events, _from, state) do
Logger.info("Consumer State: #{state}")
words = Enum.join(events)
sentence = state <> words
Logger.info("Final State: #{sentence}")
{:noreply, [], sentence}
end
endElixir is a very explicit language and you will see this being the norm in almost all libraries for the ecosystem. GenStage is not different.
So, you maybe wondering how a consumer knows which producer to ask data from?
When you initiate a Consumer you explicitly tell the producer it will be subscribed to by using this part of the code:
subscribe_options = [{Producer, min_demand: 0, max_demand: 10}]
{:consumer, args, subscribe_to: subscribe_options}
The consumer contract especifies that you should return a tuple with the first item being the atom :consumer . The option subscribe_to is not required but if you don’t set it you will need to sync the consumer to the producer in another place.
And how do you run this code?
You can open the console with:
cd to_your_project
iex -S mixInside the console you will run:
iex> Post.Producer.start_link("Some weird sentence. Maybe you want to reveal that you are The Batman, so you saw: I'm Batman")
{:ok, some_pid}
iex> Post.Consumer.start_link()As soon as you start the consumer, the logs in the code show up in the console. All this example do is break the sentence into characters and send the characters to the consumer, which will then get the characters together to form the sentence again.
And that is it. You created your first GenStage flow.
But this is it? Is that more to it?
Yes. There are many more, and if you stick around, I will show you everything you need to know about GenStage.
GenStage In Depth
From the documentation:
Stages are data-exchange steps that send and/or receive data from other stages.
This was me after reading this sentence above:

Yeah. I feel you, folks. So, what the heck does that mean?
The goal of GenStage is to make it easy for you to create data flow, more like a pipe, where you can send data in one direction, way down from one component to the other.
Something like this:
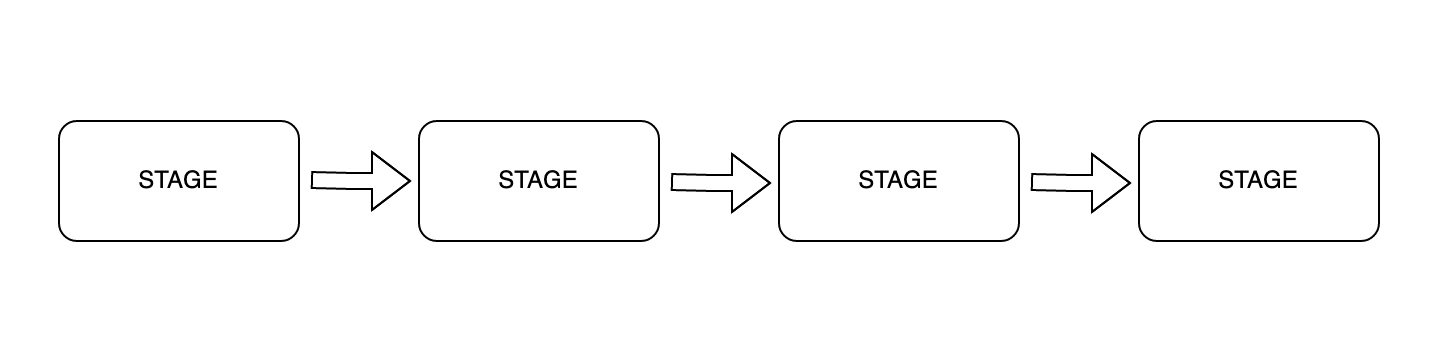
The only thing to notice here is that the first stage should be a Producer and the last stage should be a Consumer and all the stages in between are called… you guessed it right: Producer-Consumer .
That way, GenStage makes it possible to establish a data flow where each stage can do a specific job before sending the data down to the next stage. But there is more to it.
You can make multiple consumers consume from one producer and create multiple producer-consumers to consume from other producer-consumers. The way you arrange the flow of data with your stages is endless. So you can do whatever you want to, and that is the beauty of it.
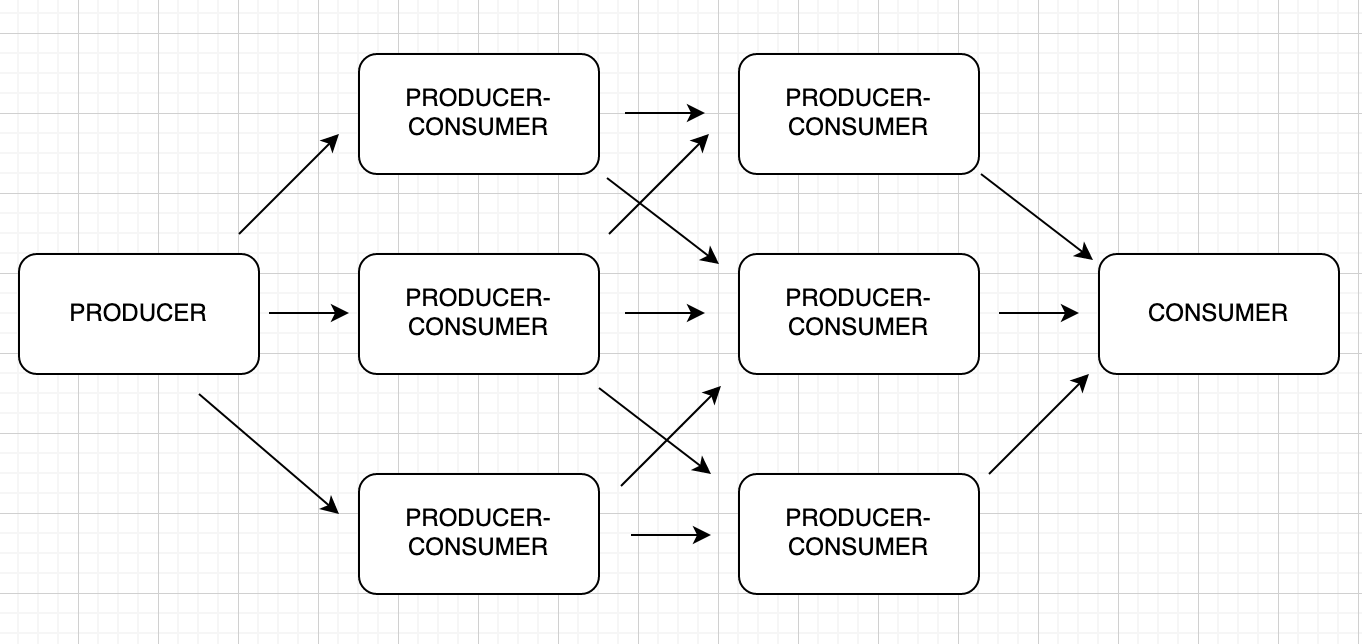
Wait a minute! With all that options, how should I use this?
First you need to understand that:
GenStage is not made to organize your code
When you start creating your stages, you will maybe think that it would be a great idea to have a producer-consumer deal with one part of the logic and then send the data to another producer-consumer to deal with another part of the logic and down to the rabbit hole but this is considered an anti-pattern.
Instead, you need to create consumers or producer-consumers to deal with concurrency and back-pressure problems and never organize your code around GenStages.
Keep your code in business domain modules apart from any infrastructure, whether it’s a GenStage, a GenServer, or any other Gen* .
GenStage as a mechanism of data flow, concurrency, and back-pressure
When you create a flow of data with GenStage, you need to think about runtime properties, such as concurrency and data transfers, and create or re-arrange your stages to wherever you need to deal with more concurrency or back-pressure.
By the way, what is back-pressure anyway?
Imagine you are a rockstar, and a bunch of people outside want to talk with you. If you open the gate and let everyone come in simultaneously, you will be able to speak with one or two, but you will not hear everyone else because they will be talking simultaneously. What do you do then?
You apply back pressure. You put a security person at the door and let your fans enter, but only 5 at a time. This way, you can talk with all of them in groups of five, and everyone will be pleased at the end. (this explanation was stolen or kind of from Svilen Gospodinov in his book concurrent data processing with elixir).
That’s it. Back pressure is a mechanism to control data flow so we don’t become overwhelmed or lose any data in the process. By the way, back-pressure is a term commonly used in the mechanics of fluids, and a more concise explanation is on Wikipedia and goes like this:
Back pressure (or backpressure) is a resistance or force opposing the desired flow of fluid through pipes, leading to friction loss and pressure drop. The term back pressure is a misnomer, as pressure is a scalar quantity, so it has a magnitude but no direction.
How GenStage applies back-pressure?
GenStage applies backpressure by inverting the flow control from the producer to the consumer. So instead of a producer checking, if it can send data to consumers (or doesn’t check at all and overwhelm the system), the consumers will send a message to the producers with the exact demand they want. This image will help you understand how it goes.
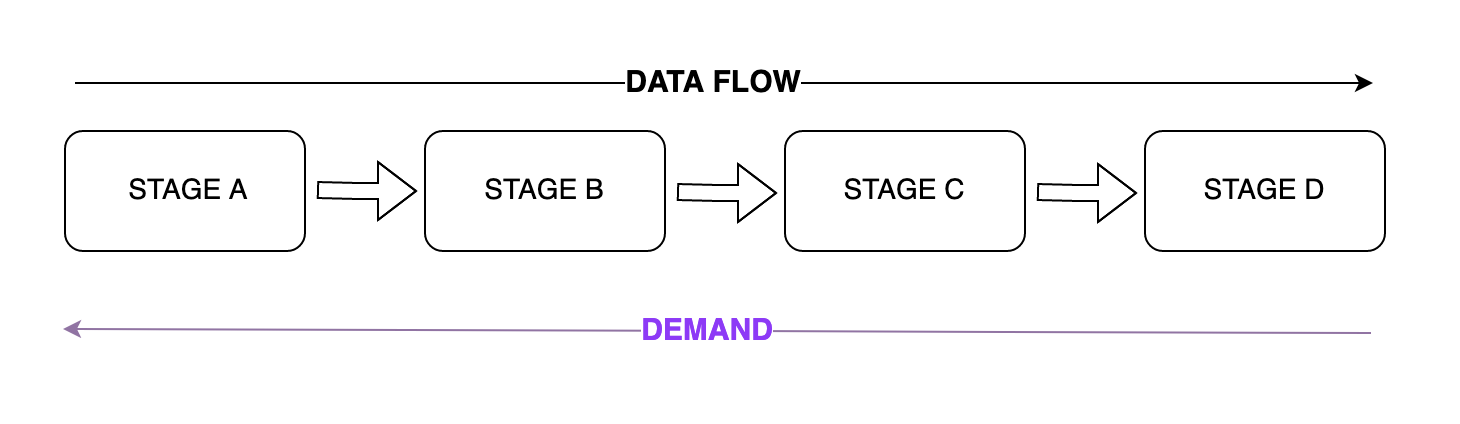
As you can see, the demand goes right to the left, and the data flow goes from left to right. That way, the consumer controls the data flow by sending the demand to the producers. Now that you understand how GenStage deals with bak-pressure, it’s time to know about the components that compose this library.
GenStage Components
As we talked about earlier gen stage has 3 main components:
- Producer
- Consumer
- Producer-Consumer
And in this section we are going to talk about all of them. Starting with the simpler one: the producer.
Producer
Responsible for producing data to send to the consumers, the producer will get the data from any source you specify and send the demanded amount to the consumers. A producer has two main callbacks that you will need to implement, but first, here is a simple example of a producer.
defmodule Producer do
use GenStage
def start_link(args \\ []) do
GenStage.start_link(__MODULE__, %{events: args}, name: __MODULE__)
end
def init(initial_state) do
{:producer, initial_state}
end
def handle_demand(demand, state) do
events =
if state.events >= demand do
state.events
else
get_data_from_some_source()
end
{events_to_dispatch, events_remained} = Enum.split(events, demand)
{:noreply, events_to_dispatch, %{state | events: events_remained}}
end
endSo, let’s break it down a little bit. As I said we have two callbacks and they are:
- init(state)
- handle_demand(demand, state)
The init will handle the initialization of the process, and the handle_demand will be fired when the consumers demand data to be processed. What needs to be clarified is how to send the data to the consumers when you get more data from the source than the consumers have asked. And because this could be a common behavior, the handle_demand returns a tuple with three elements.
-
:no_reply-> this is a required atom to be returned by the function - events_to_dispatch -> All the events that will be sent to the consumer
-
state -> This is the up-to-date state for the producer. The next time the
handle_demandfunction is called, it will be this state that will be passed to the state parameter in the function.
This way, the producer can answer the demand of the consumer and doesn’t need to go to the source every time. It will only go to the source to get more data if the demand being asked for is bigger than the events left in the state.
Explaining the max_demand and min_demand
GenStage is built in a way that it always wants to make sure the consumer has work to do. So, the way the consumer asks for demand from the producer uses simple logic to make sure the consumer will not be idle.
events_to_process = max_demand - min_demandAlthough it is a simple formula, it is tricky sometimes, and it is better to show an example. Imagine we have:
- max_demand = 100
- min_demand = 50
The first time the consumer asks for data, it will ask for the 100 (max_demand) because the consumer is greedy and wants everything it can possibly process.
But the consumer will not process 100 events in the same batch. It will split the batch using the formula above, so in this case, the max_demand = 100 and the min_demand = 50, so the events will be split into two batches of 50. When the consumer finishes processing the first batch, it will send a new demand to the producer, but this time it will send 50 as the demand because it already processed 50. This diagram shows better:
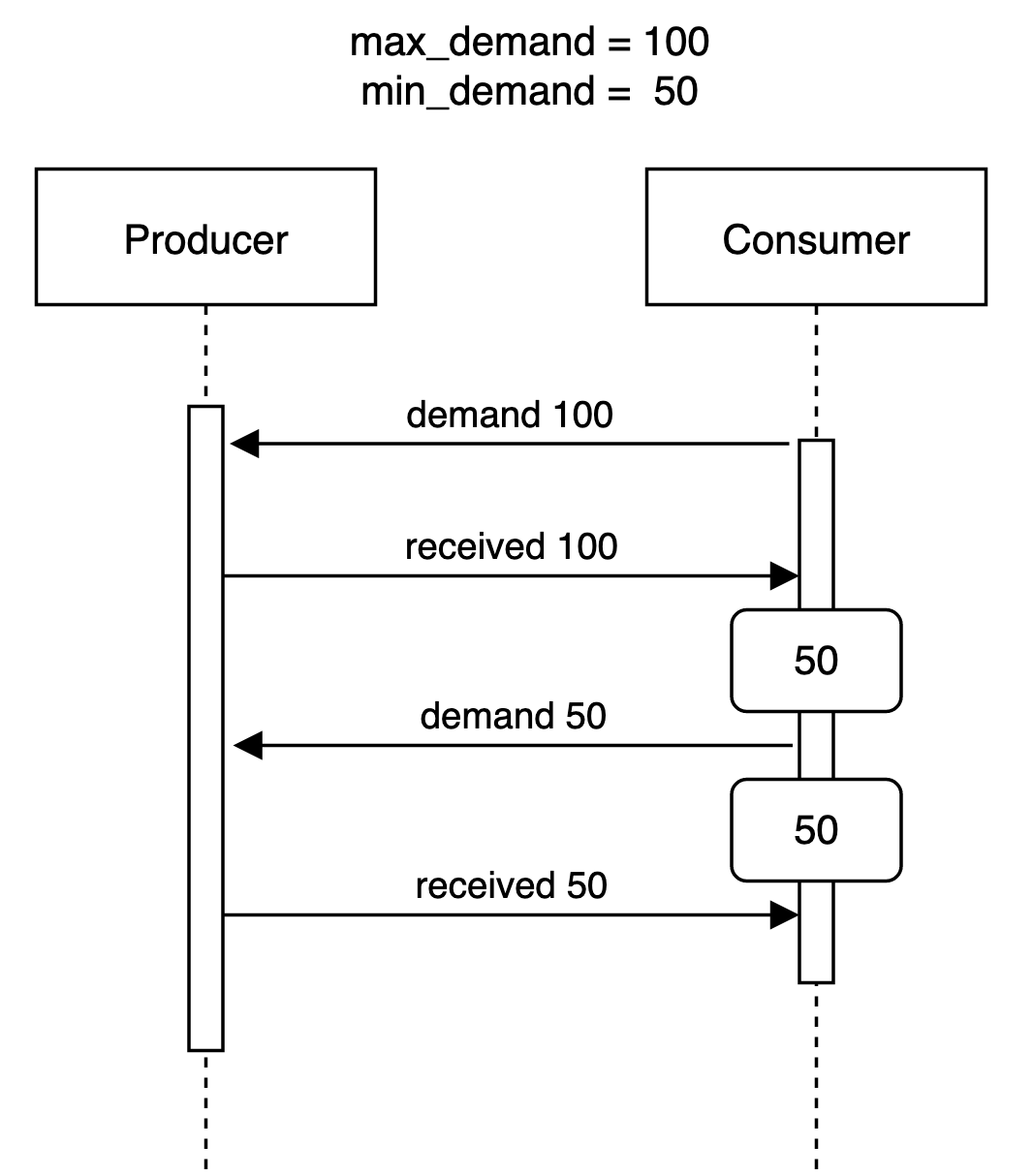
To quote Svilen from his book Concurrent Data Processing In Elixir:
“By tracking the number of events a consumer processes and number of events in progress, GenStage optimizes the flow of data for peak efficiency, keeping both consumers and producers busy at all time.”
Consumer
Like the name says, a gen-stage consumer is a component that subscribes to events and generates the demand for producers or producer-consumers. A consumer is always at the end of a data flow and never in the middle or the beginning, as a consumer’s only job is to subscribe to and receive events from producers / producer-consumers. But how does it do this? Let’s break down the components of the consumer now. Here is an example of the consumer
defmodule Consumer do
use GenStage
alias Producer
def start_link(args) do
GenStage.start_link(__MODULE__, args)
end
def init(args) do
{:consumer, args, subscribe_to: [Producer]}
end
def handle_events(events, from, state) do
{:noreply, [], state}
end
end
Let’s understand all the parts. First, we have the use GenStage. Yes, you guessed right, this is required to make our Consumer module a GenStage. Like GenServer or Agent, we need to use the use macro to transform our module into a GenStage.
Like GenServer, GenStage is a process with two main functions we need to implement.
- init(args)
- handle_events(events, from, state)
The init is a function that will be called after we call GenStage.start_link, and it is responsible for initializing the GenStage with the settings you set when implementing the function. For the consumer, it is required that we return a tuple with the first item being an atom :consumer, the second item being any arguments you want to initialize the consumer with, and the third item needing to be a map of options. For the third item, you can set the subscribe_to key. This key will receive as a value a list. This list needs to include the producer module or the producer-consumer module, as shown in the example above.
You can also pass a list of tuples where the tuple will be: {ProducerModule, options} . We will discuss those options later. By initializing the consumer setting the subscribe_to option, the consumer will be automatically subscribed to the producer and can start receiving events right as soon as it is initialized.
The other required function to be implemented is the callback handle_events(events, from, state). This is where you will manage all the events being received by the consumer. This function will always receive, at most, the number of events specified in the max_demand option (see the Twitter example at the beginning of the article). The events are the data sent by the producer to the consumer and can be in any format. The function also receives the from parameter that contains the PID of the producer or producer-consumer process that sent the events. At last, it also receives the state, which is the latest state of this consumer.
This function needs to return a tuple like: {:noreply, [], state}
When GenStage first calls this callback, the state returned will be empty, but for the subsequent iterations, as long as this consumer process does not die, the state will be whatever the state will return in the function.
It is required for the consumer to return the second param in the tuple as an empty list [] because the consumer can never emit items/events.
About the options in the {ProducerModule, options}
You may be wondering the different ways we can initialize the consumer. Here I will show you some.
-
Without subscribing to any producer:
def init(args) do {:consumer, args} endThis way the consumer will not subscribe to any producer and the you will need to call
GenStage.sync_subscribe(ConsumerModuleName, to: ProducerModuleName)later on to subscribe a consumer to a producer. -
With subscribe_to option:
def init(args) do {:consumer, args, subscribe_to: [Producer]} endHere the consumer will be subscribed to a producer as soon as it initializes.
-
With more options:
def init(args) do subscribe_options = {[Producer, min_demand: 0, max_demand: 10, cancel: :permanent]} {:consumer, args, subscribe_to: subscribe_options} endThe options are mostly self-explanatory and I will link here so you can check them out later if you are curious.
Producer-Consumer
A producer-consumer can subscribe to a producer and be subscribed by another producer-consumer or a consumer. The main difference from the producer is that it can’t produce any data, and the main difference from the consumer is that it will continuously emit events at the end of the process so they can be consumed by the consumers. Here is an example of a producer-consumer:
defmodule ProducerConsumer do
use GenStage
def start_link(multiplier) do
GenStage.start_link(ProducerConsumer, multiplier)
end
def init(multiplier) do
{:producer_consumer, multiplier}
end
def handle_events(events, _from, multiplier) do
events = Enum.map(events, & &1 * multiplier)
{:noreply, events, multiplier}
end
end
The only significant difference here is that in the init callback, you are using the atom producer_consumer, and in the handle_events callback, you are actually emitting events in the no_reply tupple. You may be wondering when to use a producer-consumer. As always, the best question to this is: It depends.
You should use your best knowledge for each case, but a common approach is to use a producer-consumer to better apply back pressure. Remember, always keep your business logic code in other modules.
How to achieve concurrency?
The best and simple way to achieve concurrency with gen-stages is to subscribe more than one consumer to the producer. You need to remember that when dealing with multiple consumers, they may or may not receive the same data. Take a look at buffering and using different dispatchers in the producer to see what would be the best strategy for you.
GenStage can be hard to understand because there are multiple ways to do the same thing, and I’ve come to realize this is a good approach if you want a library to be used in a wide variety of solutions.
Cases of usage
There are two main cases of usage:
- When the process to get the data is controlled by you, you can respond to demands.
- When data is being pushed, and you can’t control the amount o data that you need to process.
For the first case, see the example below, where I show how to get data from Twitter using GenStage stages.
For the second case where you don’t know how much data will be pushed to you and you can’t control it, I found this great blog post that can help you understand this case, and you can also check the documentation linked above about buffering and gen-stage dispatchers. This article is way too big already, and the documentation is too good not to link to it
As I said, I added two main cases, but there are multiple cases of usage, and only you know your needs. As I promise at the beginning of this article, I want to show you a simple approach to how to get data from Twitter and record it into your database using gen-stage to process the flow and ecto to record the data.
Consuming Twitter Api Forever
So, I want to get all tweets mentioning the Brazilian singer Anitta. And I want to deploy a solution where I don’t need to push any button to make it work, I want to deploy, and the application will start to get tweets that mention Anitta.
So, the first thing I need to do is to get a Twitter developer account. Since this is not a Twitter tutorial, I will let you go to the developer website and set up your account.
The next step is to figure out how to get tweets that mention Anitta, and to do that, you need to go to the Twitter docs to get the exact query that we need to send to Twitter so we can get the information we need. This url is where you need to go if you want to understand how to, using their rest API, build the query to search for the tweets you wish to. I only want to get the recent tweets in this tutorial, so I went for the api.twitter.com/2/tweets/search/recent. This endpoint will return a maximum of 100 results for each request, which is important information.
This is the client we need to build so we can get the recent tweets. The main function here is the search_tweets and we are sending these parameters:
-
search_term-> This is the term that you are search for -
since_id-> This is a tweet id. You want all tweets after this one. -
max_results-> Self explanatory and you will need to get max of 100.
defmodule TwitterClient do
@moduledoc """
Simple Twitter Client to get data using a search term
"""
def search_tweets(search_term, since_id, max_results \\ 100) do
{:ok, %HTTPoison.Response{body: body}} =
HTTPoison.get(url(search_term, since_id, max_results), headers(), options())
{:ok, Jason.decode!(body)}
end
defp url(search_term, since_id, max_results) do
query = get_query(search_term, since_id, max_results)
"https://api.twitter.com/2/tweets/search/recent?query=#{query}&expansions=author_id&user.fields=location,name,username"
end
defp get_query(search_term, 0, max_results), do: "#{search_term}&max_results=#{max_results}"
defp get_query(search_term, since_id, max_results),
do: "#{search_term}&since_id=#{since_id}&max_results=#{max_results}"
defp headers do
[Authorization: "Bearer #{twitter_token()}", Accept: "Application/json; Charset=utf-8"]
end
defp options do
[ssl: [{:versions, [:"tlsv1.2"]}], recv_timeout: 5000]
end
defp twitter_token do
Application.get_env(:twitter_trend, :twitter_token)
end
endStoring Tweets
You need to store the tweets, and to do that you will need to create an schema and a migration. So let’s do that now.
Here we are creating the migration file. Give a special attention to the fact that we are setting a unique index to the tweet_id . You will use this unique key so you don’t store duplicated tweets.
defmodule TwitterTrend.Repo.Migrations.CreateTweets do
use Ecto.Migration
def change do
create table(:tweets) do
add :text, :text
add :tweet_id, :bigint
add :tweet_author_id, :bigint
timestamps()
end
create unique_index(:tweets, [:tweet_id])
end
endAnd this is the schema:
defmodule TwitterTrend.Domain.Tweet do
use Ecto.Schema
import Ecto.Changeset
schema "tweets" do
field(:text, :string)
field(:tweet_id, :integer)
field(:tweet_author_id, :integer)
timestamps()
end
@required_fields [:text, :tweet_id, :tweet_author_id]
def changeset(tweet, attrs) do
tweet
|> cast(attrs, @required_fields)
|> validate_required(@required_fields)
|> unique_constraint(:tweet_id)
end
end
Let’s say you also want to record information for the tweet authors. In this case, you will need to add a new schema model for the TweetAuthor so you can record the informations to it. I opted to not do this because modeling a tweet domain is not the main point of the article.
Now the main part
Consumer
Now, let’s take a look at the consumer. This consumer will get the tweets as events sent by the producer and use Ecto to store the data in the database.
defmodule TwitterTrend.GenStage.TweetConsumer do
use GenStage
require Logger
alias TwitterTrend.GenStage.TweetProducer
def start_link(args) do
GenStage.start_link(__MODULE__, args)
end
def init(args) do
subscribe_options = [{TweetProducer, min_demand: 0, max_demand: 10}]
{:consumer, args, subscribe_to: subscribe_options}
end
def handle_events(events, _from, state) do
Enum.each(events, fn event ->
Logger.info("Event Received by #{state}: #{event.tweet_id}")
TwitterTrend.save_tweet(event)
end)
{:noreply, [], state}
end
end
This consumer is as simple as it gets. I set the max_demand to 10 but you can bump this. For this case I don’t think you will gain much by setting to more than 100 since the twitter API has this hard limit per request. The handle_events will loop trough the events and will save one tweet at time. You can gain some time and change to do a bulk insert here. I will let as an exercise for you. the TwitterTrend has nothing unsual. Here it is the save_tweet function:
def save_tweet(tweet) do
%Tweet{}
|> Tweet.changeset(Map.from_struct(tweet))
|> Repo.insert(on_conflict: :nothing)
end
The key here is to use the on_conflict: :nothing so we will discard the data if we already have a tweet with the same tweet_id. Remember that you set the unique_key for the tweet_id when you did the migration.
Producer
In this case the producer is where the bulk of the work will happen. Let’s first show the code and then I will go through it.
defmodule TwitterTrend.GenStage.TweetProducer do
use GenStage
alias TwitterTrend.TwitterParser
@wait_milliseconds 20000
def start_link(search_term) do
initial_state = %{since_id: 0, tweets: [], search_term: search_term}
GenStage.start_link(__MODULE__, initial_state, name: __MODULE__)
end
def init(initial_state) do
{:producer, initial_state}
end
def handle_info({:more_tweets, demand}, state) do
tweets = get_tweets(state.search_term, state.since_id)
latest_tweet_id = get_latest_tweet_id(tweets, state)
{tweets_to_process, tweets_that_left} = Enum.split(tweets, demand)
new_state =
if tweets_to_process == [] do
get_more_tweets_after_wait(demand, @wait_milliseconds)
state
else
Map.merge(state, %{tweets: tweets_that_left, since_id: latest_tweet_id})
end
{:noreply, tweets_to_process, new_state}
end
def handle_demand(demand, state) do
case state.tweets do
[] ->
tweets = get_tweets(state.search_term, state.since_id)
latest_tweet_id = get_latest_tweet_id(tweets, state)
{tweets_to_process, tweets_that_left} = Enum.split(tweets, demand)
new_state = Map.merge(state, %{tweets: tweets_that_left, since_id: latest_tweet_id})
if tweets_to_process == [], do: get_more_tweets_after_wait(demand, @wait_milliseconds)
{:noreply, tweets_to_process, new_state}
tweets ->
{tweets_to_process, tweets_that_left} = Enum.split(tweets, demand)
new_state = Map.merge(state, %{tweets: tweets_that_left, since_id: state.since_id})
if tweets_that_left == [], do: get_more_tweets_after_wait(demand, @wait_milliseconds)
{:noreply, tweets_to_process, new_state}
end
end
defp get_tweets(search_term, since_id) do
case TwitterClient.search_tweets(search_term, since_id) do
{:ok, %{"data" => tweets}} ->
TwitterParser.call(tweets)
{:ok, %{"meta" => %{"result_count" => 0}}} ->
[]
end
end
defp get_more_tweets_after_wait(demand, wait) do
Process.send_after(self(), {:more_tweets, demand}, wait)
end
defp get_latest_tweet_id([], state), do: state.since_id
defp get_latest_tweet_id(tweets, _state), do: List.last(tweets).tweet_id
end
Let’s break it down. First the start_link function where we start the process. Here we are also setting the state:
-
initial_state = %{since_id: 0, tweets: [], search_term: search_term}We set thesince_idto 0 and initialize thetweetslist and ge thesearch_term
The next important piece of code is the handle_demand:
def handle_demand(demand, state) do
case state.tweets do
[] ->
tweets = get_tweets(state.search_term, state.since_id)
latest_tweet_id = get_latest_tweet_id(tweets, state)
{tweets_to_process, tweets_that_left} = Enum.split(tweets, demand)
new_state = Map.merge(state, %{tweets: tweets_that_left, since_id: latest_tweet_id})
if tweets_to_process == [], do: get_more_tweets_after_wait(demand, @wait_milliseconds)
{:noreply, tweets_to_process, new_state}
tweets ->
{tweets_to_process, tweets_that_left} = Enum.split(tweets, demand)
new_state = Map.merge(state, %{tweets: tweets_that_left, since_id: state.since_id})
if tweets_that_left == [], do: get_more_tweets_after_wait(demand, @wait_milliseconds)
{:noreply, tweets_to_process, new_state}
end
end
The first time the consumer asks for tweets, the state.tweets will be empty, so the first case will be used. Here you will get the tweets. You will also get the latest_tweet_id. Next line, you will use the Enum.split to get the split into two lists, one with the demand of tweets the consumer is asking, and the other is the rest. You use this to create the new_state that will be passed at the end of the function.
One gotcha is that the tweets can be empty. So, when splitting the list, the tweets_to_process will also be empty, and you will need to check that if it is empty, call the Twitter API after some time and just return the tuple {:noreply, tweets_to_process, new_state} and in this case, the tweets_to_process will be empty.
At some point, you will get tweets, and the consumer will send a demand, and after sending the demanded tweets to the consumer, you will still have more tweets to send. In this case, the next time a consumer asks for more tweets, the case condition will be the second one where it still has mode tweets to process before going to the Twitter API again. In this case, after you Enum.split and set the new_state, you will also need to check if there are no more tweets left and if so, call the Twitter API again after the waiting period.
Since we are calling the get_more_tweets_after_wait function, this function will eventually call the handle_info callback:
def handle_info({:more_tweets, demand}, state) do
tweets = get_tweets(state.search_term, state.since_id)
latest_tweet_id = get_latest_tweet_id(tweets, state)
{tweets_to_process, tweets_that_left} = Enum.split(tweets, demand)
new_state =
if tweets_to_process == [] do
get_more_tweets_after_wait(demand, @wait_milliseconds)
state
else
Map.merge(state, %{tweets: tweets_that_left, since_id: latest_tweet_id})
end
{:noreply, tweets_to_process, new_state}
end
This function will get tweets and basically do the same process of updating the state and return the tweets to be processed. If after the wait period you still dont have any tweet to process it will call the get_more_tweets_after_wait again and return the old state.
But how do we start this process. In this case I want to start the process as soon as the application starts and the best place to do this is add the initialization to the application.ex:
defmodule TwitterTrend.Application do
use Application
@impl true
def start(_type, _args) do
children = [
# Start the Ecto repository
TwitterTrend.Repo,
# Start the Telemetry supervisor
TwitterTrendWeb.Telemetry,
# Start the PubSub system
{Phoenix.PubSub, name: TwitterTrend.PubSub},
# Start the Endpoint (http/https)
TwitterTrendWeb.Endpoint
# Start a worker by calling: TwitterTrend.Worker.start_link(arg)
# {TwitterTrend.Worker, arg}
{TwitterTrend.GenStage.TweetProducer, "anitta"},
Supervisor.child_spec({TwitterTrend.GenStage.TweetConsumer, "Consumer 1"}, id: :consumer_1),
Supervisor.child_spec({TwitterTrend.GenStage.TweetConsumer, "Consumer 2"}, id: :consumer_2)
]
opts = [strategy: :one_for_one, name: TwitterTrend.Supervisor]
Supervisor.start_link(children, opts)
end
endI know and you should be aware that this could not be the best way to start a producer because this way you are setting the search term hard coded in the main file of the application. But for our case it is enough. Here I am starting passing the specified search term and two consumers. And because we are initializing two consumers we need to set different ids so we can have two consumers each one with their respective id.
And after this very long post I will finish with a phrase from Marcus Aurelius:
If it’s endurable, then endure it. Stop complaining.
Some of the concepts mentioned here can be easy to some and hard to others and it all depends in which step in the ladder you are. As everything in life, keep going, keep studying, keep chalenging yourself. That’s is the only way.
As Yoda said once:
Do or do not. There is no try.